behind pipeline(huggingface)
behind pipeline
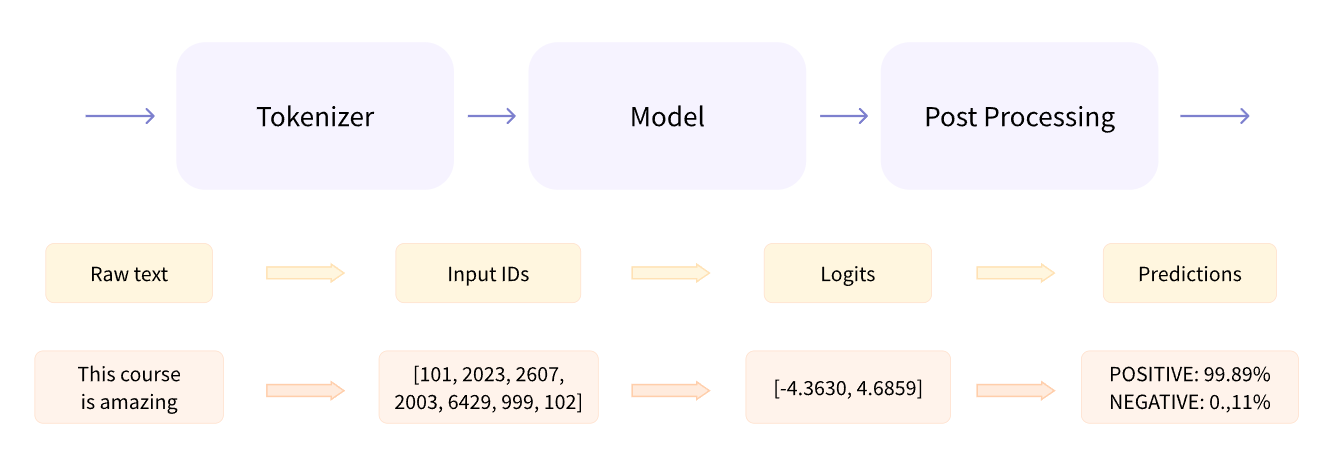
tokenizer
我们使用的tokenizer必须跟对应的模型在预训练时的tokenizer保持一致,也就是词表需要一致。
Huggingface中可以直接指定模型的checkpoint的名字,然后自动下载对应的词表。
- 主要参数包括:
- text,可以是单条的string,也可以是一个string的list,还可以是list的list
- padding,用于填白
- truncation,用于截断
- max_length,设置最大句长(与truncation一起使用,表示每个长度为max_length就截断)
- return_tensors,设置返回数据类型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
from transformers import AutoTokenizer
checkpoint = 'distilbert-base-uncased-finetuned-sst-2-english'
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
raw_inputs = ['Today is a good day! Woo~~~',
'How about tomorrow?'] #原始文本
"""
tokenizer(raw_inputs) #直接使用
{'input_ids': [[101, 2651, 2003, 1037, 2204, 2154, 999, 15854, 1066, 1066, 1066, 102], [101, 2129, 2055, 4826, 1029, 102]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1]]} #此处两个序列长度不一
"""
"""
tokenizer(raw_inputs, padding=True) #padding用于序列长度对齐使用,通过补0实现
{'input_ids': [[101, 2651, 2003, 1037, 2204, 2154, 999, 15854, 1066, 1066, 1066, 102], [101, 2129, 2055, 4826, 1029, 102, 0, 0, 0, 0, 0, 0]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0]]}
"""
return_tensors属性也很重要,用来指定返回的是什么类型的tensors,pt就是pytorch,tf就是tensorflow
model
也可以通过AutoModel来直接从checkpoint导入模型。
这里导入的模型,是Transformer的基础模型,接受tokenize之后的输入,输出hidden states,即文本的向量表示,是一种上下文表示。
这个向量表示,会有三个维度:
- batch size
- sequence length
- hidden size
1 2
from transformers import AutoModel model = AutoModel.from_pretrained(checkpoint)
加载了模型之后,就可以把tokenizer得到的输出,直接输入到model中:
1 2 3
inputs = tokenizer(raw_inputs, padding=True, truncation=True, return_tensors='pt') outputs = model(**inputs) # 这里变量前面的**,代表把inputs这个dictionary给分解成一个个参数单独输进去 vars(outputs).keys() # 查看一下输出有哪些属性
post-processing
后处理主要就是两步:
把logits转化成概率值 (用softmax) 把概率值跟具体的标签对应上 (使用模型的config中的id2label)
1
2
3
import torch
predictions = torch.nn.functional.softmax(outputs.logits, dim=-1) # dim=-1就是沿着最后一维进行操作
predictions
输出:
1
2
tensor([[1.4276e-04, 9.9986e-01],
[7.3341e-01, 2.6659e-01]], grad_fn=<SoftmaxBackward>)
得到了概率分布,还得知道具体是啥标签吧。标签跟id的隐射关系,也已经被保存在每个pretrain model的config中了, 我们可以去模型的config属性中查看id2label字段:
1
2
id2label = clf.config.id2label
id2label
输出:
1
{0: 'NEGATIVE', 1: 'POSITIVE'}
综合起来,直接从prediction得到标签:
1
2
for i in torch.argmax(predictions, dim=-1):
print(id2label[i.item()])
输出:
1
2
POSITIVE
NEGATIVE
This post is licensed under CC BY 4.0 by the author.